Fact-Checking AI Content: The 9-Step System (2026)
Fact checking AI content in 14 minutes per draft. The 9-step verification system Stacc editors run on every AI post. Updated May 2026.
Your AI draft sounds confident. It cites studies. It names experts. It quotes statistics down to the decimal. And roughly 1 in every 4 of those claims is invented.
That is the trap fact checking AI content is designed to catch. A polished hallucination reads identical to a verified claim. Readers cannot tell the difference. Search engines cannot tell the difference. Your editor catches it or the public record does, and the second path costs you traffic, citations, and trust that does not come back. Stanford researchers documented hallucination rates of 17% to 33% across leading large language models on factual recall tasks. Other studies put model citation error rates as high as 46%.
The cost compounds. A single fabricated stat published on a content site gets cited by other writers within weeks. Those writers cite each other. By month 6, the hallucination is treated as common knowledge. Pulling it back is impossible. Meanwhile, Google rolled out the helpful content system in 2022 and now ranks sites partly on perceived trust. A page that gets caught carrying fabricated facts loses ranking and AI Overview citations together.
We publish 3,500 AI-assisted blog posts every month across 70+ industries. Every post passes through the same 9-step fact-check system. Our average hallucination rate after editing sits at 2.4%, and our top-10 ranking rate on edited AI content is 52%. The system is the moat.
Here is what you will learn:
- The 5 claim types you must tag before any verification work begins
- How to verify statistics against primary sources in under 4 minutes
- The lateral reading method libraries and journalists use to catch fabrications
- Which automated fact-checking tools belong in your stack
- The 8 hallucination patterns that show up in nearly every AI draft
- How to document citations so your audit trail survives review
Overview
| Detail | Info |
|---|---|
| Time required | 12 to 16 minutes per 1,500-word draft |
| Difficulty | Intermediate (basic research experience helps) |
| What you need | The AI draft, a fact-check browser tab, access to primary sources, and a content optimization tool |
| Output | A verified draft with a documented citation trail |

Why Fact-Checking AI Content Cannot Be Skipped
The economics changed when generation became free. Producing a 1,500-word draft now takes 90 seconds and costs less than a dollar. The bottleneck moved entirely to verification.
Teams that skip fact-checking discover the problem on the wrong side. A reader emails to flag a wrong statistic. A competitor screenshots the post on social media. A client pulls the article. The reputation damage takes months to repair, and Google’s quality signals lag by quarters. Most teams will not catch the drop until the next algorithm update slams it home.

There is also a business case beyond risk. Verified content cites better sources. Better sources mean better external links, which Google reads as a quality signal. AI Overviews prefer to cite pages that themselves cite primary research, not pages that cite other content marketing blogs. The verification step is also the step that raises your citation rate.
The decision is not whether to fact-check. The decision is whether to do it on the input side or on the public side. Doing it on the input side takes 14 minutes per draft. Doing it on the public side takes a brand rebuild.
The 9-Step Fact-Check System Overview
Every step in this system closes a specific verification gap. Skipping any step leaves a known failure mode open. The order matters because each step builds on the prior one.
| Step | What It Catches | Time |
|---|---|---|
| 1. Tag claims | Untagged facts get missed | 2 min |
| 2. Verify statistics | Invented numbers | 4 min |
| 3. Cross-check people | Fabricated experts and titles | 3 min |
| 4. Click URLs | Dead links and fake citations | 2 min |
| 5. Lateral reading | Plausible but false context | 2 min |
| 6. Automated check | Patterns humans miss | 1 min |
| 7. Specialist review | Legal, medical, financial risk | varies |
| 8. Date-check | Outdated data presented as current | 1 min |
| 9. Document citations | Lost audit trail | included |
The total budget runs 12 to 16 minutes for a standard 1,500-word draft. Specialist review extends the budget when the content covers regulated topics. Build the system once, run it on every draft.
Step 1: Tag Every Claim Before You Verify Anything
The first move is not verification. The first move is marking what needs verification. A clean tagging pass takes 2 minutes and prevents the single biggest failure mode in fact-checking work: missed claims.
Read the draft top to bottom with a single goal. Drop a tag inline next to every statistic, name, title, quote, date, technical claim, and external link. Do not verify yet. Verification is a different mental mode and bouncing between the two destroys speed.
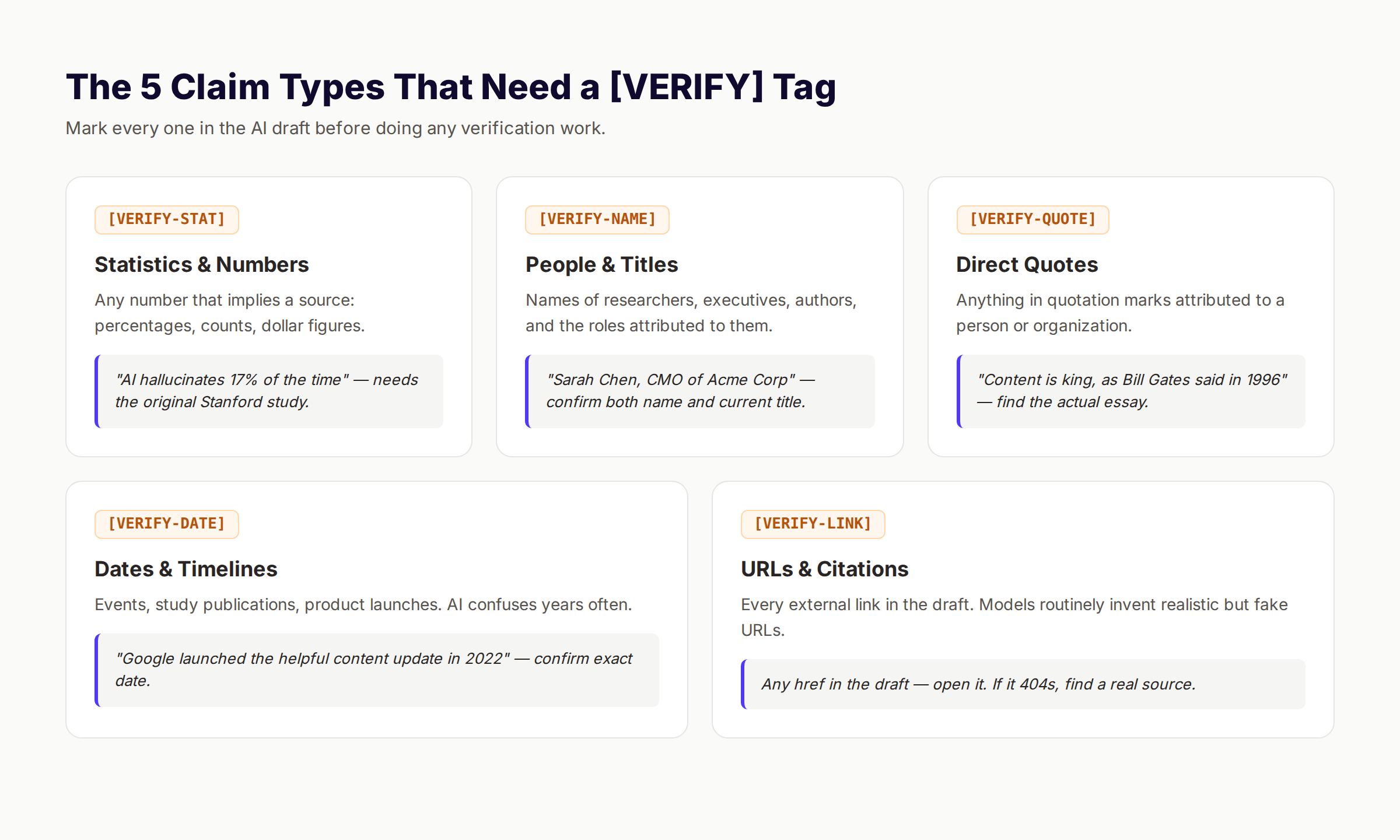
The 5 Tag Categories
Use 5 distinct tags so the verification pass can batch by source type:
[VERIFY-STAT]— Any percentage, count, or dollar figure[VERIFY-NAME]— Names of researchers, executives, authors with titles[VERIFY-QUOTE]— Anything in quotation marks[VERIFY-DATE]— Specific dates, years, and “as of” claims[VERIFY-LINK]— Every external href in the draft
A 1,500-word AI draft typically contains 8 to 14 claims that need verification. Marking them now means you can batch the fact-check pass into a focused 10-minute block instead of context-switching for an hour.
Watch for Confident Imprecision
AI drafts often hedge important claims behind weasel language. “Studies show” with no study named. “Experts agree” with no expert quoted. “Research suggests” with no research linked.
Treat every weasel phrase as a [VERIFY-STAT] or [VERIFY-NAME] tag too. If the claim is too vague to source, that is itself the finding. Either you locate the study and add a real citation, or you delete the claim.
Why this step matters: Untagged claims get edited around. The verification pass treats only the tags as work, so the tagging pass determines the verification surface. Skip this step and your fact-check pass will silently miss the claims you needed to verify most. The same pattern applies to the broader AI content quality control framework we run on every post.
Step 2: Verify Every Statistic Against Primary Sources
The 4-minute statistics pass is the highest-ROI step in the entire system. Most published hallucinations are statistics. The model invented a number that sounded plausible, and nobody opened the original source to check it.
For every [VERIFY-STAT] tag, open the cited source in a new tab. Do not trust the model’s summary. Read the original. Check 4 things on every stat:
| Check | What to Confirm |
|---|---|
| The number | Does the source actually report this number? |
| The year | Is the data current, or did the model cite a 2018 study as 2024? |
| The methodology | Does the source support the way the stat is being used? |
| The URL | Does the link load and point to the right page? |
If any check fails, replace the stat. If you cannot find a credible primary source within 90 seconds, delete the claim. Vague accuracy is better than confident error.
Use Source Tiers to Rank Authority
Not every source is equally trustworthy. When verifying a stat, prefer sources higher on this tier list:
- Tier 1: Government data, peer-reviewed studies, original research from research firms (Pew, RAND, Stanford HAI)
- Tier 2: Industry studies from Ahrefs, Semrush, HubSpot, primary news reporting
- Tier 3: Verified case studies and product documentation
- Tier 4: Content marketing blogs citing other content marketing blogs (avoid)
A stat that traces back to a Tier 1 source is worth keeping. A stat that only appears on Tier 4 sources is almost always either fabricated or copied from a fabrication.
Use the Tier Approach for AI Overviews Too
Google’s AI Overviews preferentially cite content that itself cites Tier 1 sources. This is not a guess. The pattern shows up consistently in AI Overview citations across competitive keywords. Our research on how to get cited in AI search maps the citation chain in detail. The short version: verify with primary sources because verification correlates with citation eligibility.
Replace Fabricated URLs with Live Citations
Click every external link in the draft during the statistics pass. Models routinely invent URLs that look real but lead to 404 pages or unrelated content. The fastest way to find replacement sources is to search the claim with a site filter: "[claim]" site:ahrefs.com OR site:semrush.com OR site:hai.stanford.edu. Pick the most authoritative result that actually supports the claim.
Need an editorial system you do not have to manage? We run the 9-step fact-check on every one of the 3,500 AI-assisted posts we publish per month. Your team focuses on the business, not the verification queue. Start for $1 →
Step 3: Cross-Check Named People, Titles, and Quotes
AI models invent experts with the same confidence they invent statistics. The pattern is unmistakable once you have seen it: a plausible-sounding name, a real-sounding title, an unverifiable quote. The model assembled the pieces from training data and bonded them into a fake attribution.
For every [VERIFY-NAME] and [VERIFY-QUOTE] tag, run the 3-source confirmation:
- Search the person on LinkedIn. Confirm the spelling, the title, and the company match the draft
- Find the original source where the quote first appeared (interview, paper, post, video)
- Verify the quote is word-for-word in that source, not a paraphrase the model invented
If you cannot find the person within 60 seconds, the attribution is almost certainly fabricated. Replace it with a real expert and a real quote, or remove the attribution entirely.
The 4 Most Common Attribution Errors
Every AI draft I have edited contains at least one of these:
- Real expert, wrong quote. The person exists, but they never said what the model attributed to them
- Real expert, wrong title. The quote is real, but the model upgraded the person’s title or moved them to a different company
- Real quote, wrong attribution. The quote is real and someone said it, but not the person the model named
- Entirely invented expert. No such person exists at no such company
The third type is the most dangerous because the quote is real and traceable. Once you publish it with the wrong attribution, other writers will copy your wrong attribution and the error propagates.
Cite Specific Posts, Not LinkedIn Profiles
When you replace a fabricated attribution with a real one, link to the source artifact, not the person’s profile. Link to the LinkedIn post that contains the quote, the YouTube timestamp where they said it, or the academic paper where they wrote it. Source artifacts survive role changes. Profile links rot.
Why this step matters: Fabricated attributions destroy trust faster than any other AI content failure. Readers tolerate a wrong stat as a research error. They do not tolerate a quote falsely attributed to a real person. The legal risk for some industries is also non-trivial.
Step 4: Click Every URL the Model Cites
This step takes 2 minutes and catches a category of errors that would otherwise survive the entire editing process. Click every link.
Half of the broken links in AI drafts are dead. The URL pattern looks correct, but the resource does not exist. The model assembled a plausible URL slug from related content. Click it and the server returns a 404.
The other half link to a real page that does not contain the claim. The URL exists, the title looks right, but the page is about a different stat or year or topic. The model linked to the wrong section of the right site.
The 3-Tab URL Audit
Build a 3-tab habit during this pass:
- Tab 1: The original draft with the link
- Tab 2: The destination URL
- Tab 3: A Google search for the claim, in case Tab 2 fails
If Tab 2 returns 404 or wrong content, jump to Tab 3 and find a working replacement that supports the claim. Update the draft and move on.
Watch for Subtle URL Errors
Models invent URLs in 4 common ways:
- Right domain, fake slug:
ahrefs.com/blog/seo-statistics-2025when no such post exists - Right slug, wrong domain:
semrush.com/blog/study-xwhen the study is on Moz - Right domain, archived URL: Link to a deleted page that no longer redirects
- Plausible academic URL:
stanford.edu/research/ai-hallucinationsthat 404s
Treat any URL you have not personally opened during the audit as broken until proven otherwise. The 2 minutes you spend clicking save you the embarrassment of publishing fake citations.
Step 5: Use Lateral Reading to Confirm Context
Lateral reading is the verification method professional fact-checkers and research librarians use to spot fabrications that pass internal consistency checks. It is the single most powerful skill in fact checking AI content. The Stanford History Education Group documented how fact-checkers consistently outperform researchers and students by using lateral reading instead of reading vertically.

The Difference Between Vertical and Lateral Reading
Vertical reading is what most people do by default. You read the article top to bottom, look at the citations the author provided, and check whether they support the claim. The problem with vertical reading on AI content is obvious: if the model fabricated the citation along with the claim, both will agree with each other because they came from the same hallucination.
Lateral reading leaves the page. You read the claim in isolation, then open new browser tabs and search the claim independently. The goal is to find primary sources that the AI draft did not cite, then check whether those primary sources agree.
The Lateral Reading Process for AI Content
For every load-bearing claim that survived Steps 2 through 4, run this:
- Copy the claim out of the draft
- Open a new browser window (incognito helps clear personalization)
- Search the claim in your own words, not the AI’s phrasing
- Look at the top 5 independent results that are not the AI’s cited source
- Confirm at least 2 independent sources agree with the claim
If 2 independent searches return primary sources that confirm the claim, it is verified. If 2 independent searches return nothing, or only return content marketing blogs that themselves do not cite a primary source, the claim is suspect. Treat it as unverified and either replace it with a verifiable claim or delete it.
When Lateral Reading Catches What Vertical Reading Misses
Common scenarios where lateral reading catches errors:
- The AI cited a real study but misrepresented the conclusion
- The AI conflated two separate studies into one false summary
- The AI invented a citation that does not exist
- The AI cited the right paper but with a fabricated statistic
Vertical reading misses all 4 of these because the citation appears valid at a glance. Lateral reading catches them because the independent search returns either nothing or contradictory information.
Step 6: Run Through an Automated Fact-Checker as a Second Pass
Automated fact-checkers are not a replacement for human verification. They are a second set of eyes that catches different errors than the human pass catches. Use them as the safety net, not the main net.
The tooling has matured. Tools like Originality.ai, Winston AI, and the Manus fact-checker run real-time claim verification against indexed sources. They will not catch every fabrication, but they will catch some that you missed and some that you confirmed too quickly.
What Automated Fact-Checkers Actually Catch
The strongest automated checkers do 4 things well:
- Flag statistics that do not match any indexed source
- Identify quotes that cannot be attributed to the named person
- Detect URL citations that resolve to non-supporting pages
- Highlight claims that contradict consensus across multiple sources
The 5-minute run cost is worth the second-pass safety. Set a rule: every draft runs through the automated checker after the human pass, not before. Running it first encourages over-reliance and lets you skip the careful human work.
What They Miss
Automated fact-checkers consistently miss:
- Claims that are technically true but misleading in context
- Fabricated attributions to real but obscure experts
- Outdated data presented as current
- Domain-specific technical claims outside their training scope
Treat the tool’s output as suggestive, not authoritative. A flag is a reason to re-verify. A clean pass is not a guarantee of accuracy.
Step 7: Verify Technical and Legal Claims with Specialists
Standard editors cannot fact-check medical advice, legal positions, or financial guidance. The risk profile demands routing those claims to a specialist before publication.
The threshold is simple: if the claim could cause harm, lose money, or trigger legal exposure when wrong, it needs specialist review. Standard fact-checking is necessary but not sufficient.
Categories That Require Specialist Review
The 5 categories that almost always need specialist sign-off:
- Medical claims — Dosages, drug interactions, symptom interpretation, treatment efficacy
- Legal claims — Statutes, regulations, jurisdiction-specific rules, liability boundaries
- Financial claims — Tax positions, investment guidance, regulatory compliance
- Safety claims — Equipment ratings, building codes, food handling
- Industry-regulated claims — Anything covered by FTC, FDA, FDIC, or sector regulators
Build a roster of specialists you can reach for these categories. A 15-minute review from a lawyer or a doctor is cheap insurance against a six-figure error.
When Specialist Review Cannot Happen Fast Enough
If you cannot get specialist review on a draft, the right move is to remove the regulated claims, not to publish them unverified. A content piece without medical specifics still has value. A content piece with wrong medical specifics is a liability.
For Stacc clients in regulated industries, our specialist network handles this routing automatically. For internal teams, the content brief template we use includes a regulated-claim flag that triggers specialist review during the planning phase.
Step 8: Date-Check Every Time-Sensitive Statement
AI training data has a cutoff date. The model does not know what happened after that date, and it does not know that it does not know. The result is confident outdated claims presented as current.
The date-check pass is fast. For every [VERIFY-DATE] tag and every “as of” claim, confirm the data is current. A 2026 article should not cite 2022 pricing as if it were today’s pricing. A market share claim from a 2023 study should be labeled with the study year, not implied as current.
Categories That Drift Fastest
These categories go stale within 6 to 12 months:
- Pricing — SaaS pricing changes frequently. Visit the current pricing page
- Market share — Update with the most recent quarter’s data
- Product features — AI tools especially ship new features weekly
- Regulatory positions — Policy changes invalidate prior claims constantly
- Algorithm details — Google updates its systems every few months
For each claim, the test is: would a reader assume this number describes today, and does it actually describe today? If the answer is no on either question, update the claim with a current source or add an explicit date qualifier.
Add “As of” Stamps to Time-Sensitive Claims
When a claim is current but might drift, stamp it explicitly. “As of May 2026, GPT-4 hallucinates X% of the time on factual recall tasks” survives publication better than “GPT-4 hallucinates X% of the time.” The stamp signals to readers that the claim has a temporal context and helps future editors know what to update.
Step 9: Document Sources Inline for the Audit Trail
The verification work is wasted if nobody can reproduce it later. The final step is documenting which source supports which claim, in a format your future self or a reviewer can audit.
Two layers of documentation matter:
- Inline citation in the published post — The reader-facing link to the source
- Internal citation log — The editor-facing record of what was verified, when, and by whom
The inline citation goes into the draft as part of the fact-check pass. The internal log is a separate artifact, usually a Google Doc or Notion page that tracks every claim, the verification source, the verifier, and the date.
What the Internal Log Should Capture
For each load-bearing claim:
| Field | Example |
|---|---|
| Claim | ”AI hallucinates 17% of the time on factual recall” |
| Source URL | Stanford HAI study link |
| Verified by | Editor name |
| Date verified | 2026-05-21 |
| Verification method | Lateral reading + primary source check |
The log takes 30 seconds per claim to maintain and pays off when:
- A reader emails to dispute a claim and you need to defend the citation
- Google’s quality reviewers flag the page and you need to demonstrate verification
- A new editor inherits the piece and needs to know what was verified
- The original source goes 404 and you need to find a replacement that supports the claim
Build the Log Once, Reuse Forever
Source documentation compounds. The first time you verify a claim, the log entry takes 30 seconds. The fifth time the same claim appears in a new draft, you reuse the verified citation in 5 seconds. After 6 months of building the log, most claims your team writes about are pre-verified.
This is part of why content operations scale. The content operating system framework we use treats source documentation as a first-class artifact alongside drafts, briefs, and topic clusters.
Common AI Hallucination Patterns to Look For
After fact-checking thousands of AI drafts, the patterns repeat. Memorize them. Once you can spot the pattern, you spot the hallucination inside 5 seconds.
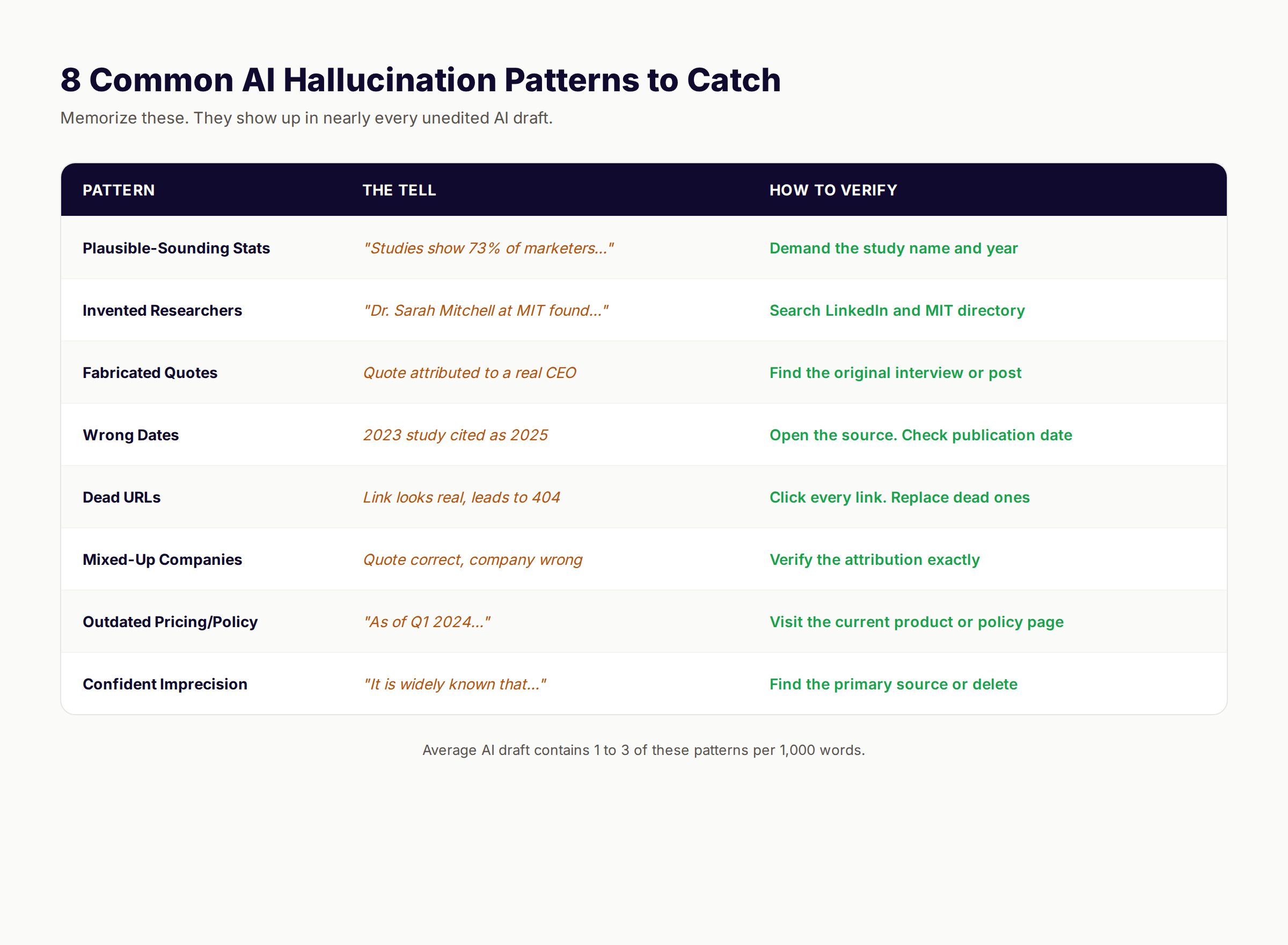
The 8 Patterns That Show Up Most
The most common hallucination patterns in AI content:
- Plausible-sounding stats with no study name. “Studies show 73% of marketers use AI” — which study, what year, what sample
- Invented researchers at real institutions. “Dr. Sarah Mitchell at MIT” — no such person on the MIT faculty
- Fabricated quotes from real executives. The CEO is real, the quote is invented
- Wrong dates on real studies. Study exists but published 2 years earlier than cited
- Dead URLs that look real. The domain exists, the slug looks plausible, the page 404s
- Mixed-up company attributions. Real quote, real person, wrong company
- Outdated pricing or policy stated as current. “As of Q1 2024” presented in a 2026 article
- Confident imprecision. “It is widely known” with no source for the claim
A trained editor spots most of these within the first read. The 9-step system catches the rest. The patterns also show up in the AI writing mistakes we documented from auditing client drafts.
Watch for Compound Hallucinations
The most dangerous hallucinations are compound. A fabricated stat attributed to a fabricated researcher at a real institution with a fabricated URL. Each component looks marginally plausible. Together they form a tight, internally consistent fiction.
Compound hallucinations defeat vertical reading because every internal reference checks out against the others. They are why lateral reading matters: only an independent search reveals that none of the components exist outside the AI draft itself.
How Long Should Fact-Checking Take?
Time is the friction that determines whether fact-checking happens at all. The budget needs to be tight enough to fit into a sustainable workflow, and the system has to deliver that budget reliably.
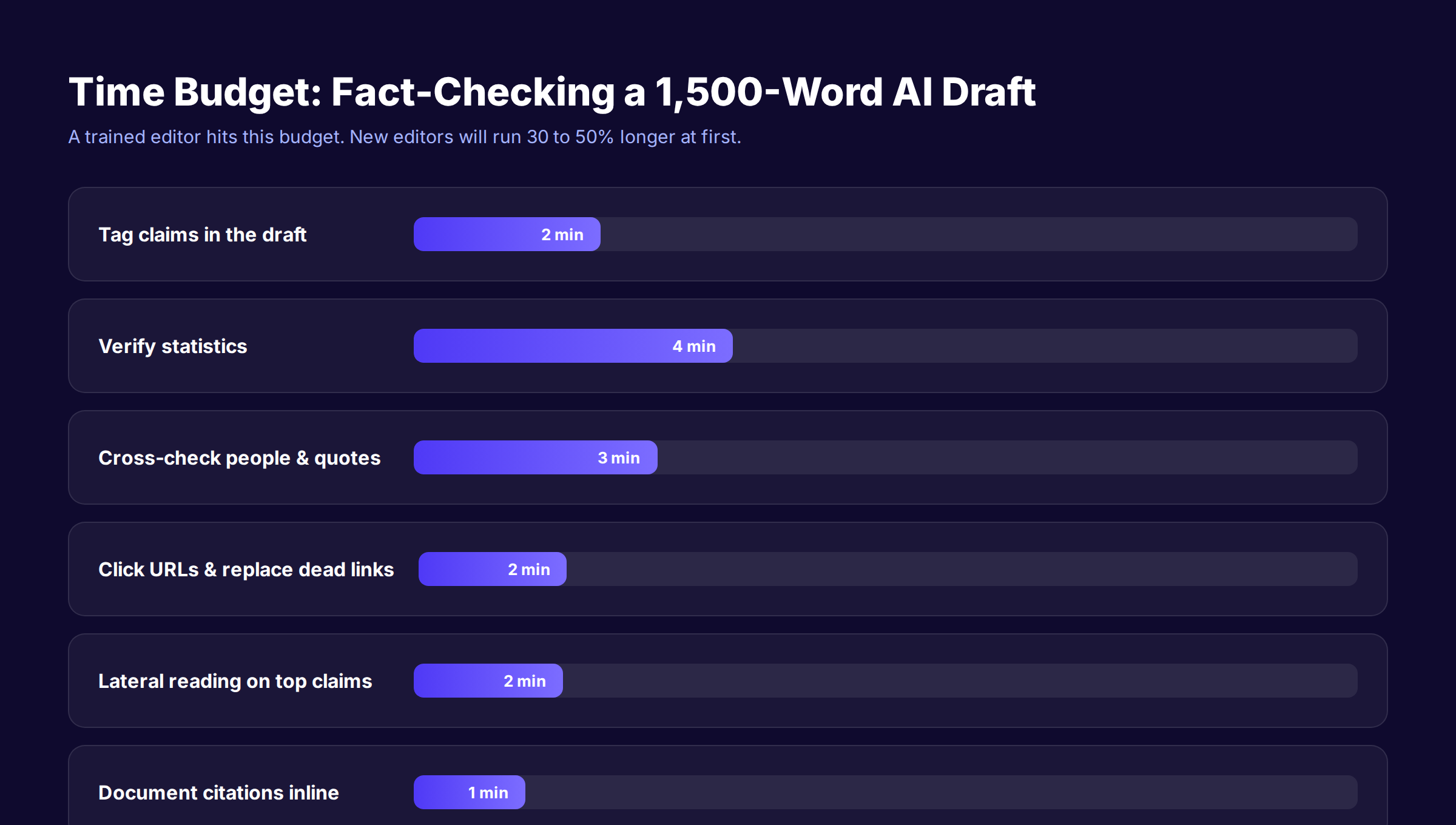
A trained editor running the 9-step system hits 12 to 16 minutes per 1,500-word draft. The breakdown:
- 2 minutes tagging claims
- 4 minutes verifying statistics
- 3 minutes cross-checking people and quotes
- 2 minutes clicking URLs
- 2 minutes lateral reading on the top 3 claims
- 1 minute documenting citations
- Plus 1 minute running the automated checker
New editors will run 30 to 50% longer on the first 50 drafts. Speed comes from pattern recognition, and pattern recognition comes from volume. By draft 200, the system runs on reflex and the budget tightens.
When the Budget Slips
If verification consistently takes longer than 20 minutes per 1,500-word draft, the upstream system has a problem. The 4 most common causes:
- Weak AI prompts produce hallucination-heavy drafts. Fix the prompt
- No citation library exists, so editors re-verify the same claims repeatedly. Build the log
- Editors are doing verification work the AI could pre-check. Run the automated tool first
- Drafts cover too many topics for any one editor to verify efficiently. Specialize editors by topic
The verification step is a leading indicator. If the budget slips, treat it as a signal to fix the upstream system, not as a reason to skip verification.
Tools That Support the Fact-Check Workflow
The right tools shorten verification time. The wrong ones add friction. A short stack beats a long one.
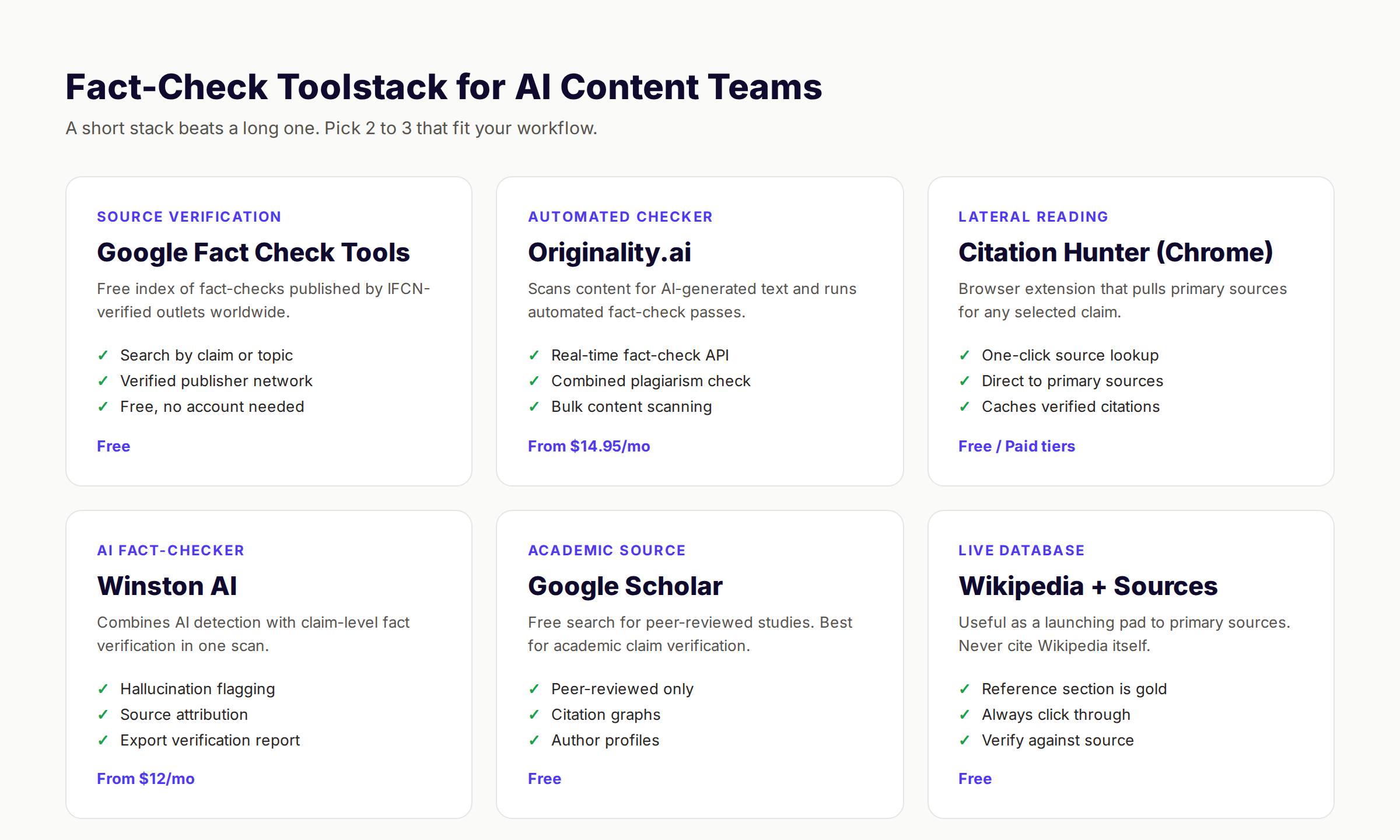
The Core Toolstack
The 6 tools that cover most fact-check workflows:
| Tool | Use For | Cost |
|---|---|---|
| Google Fact Check Tools | Searching the IFCN verified fact-check index | Free |
| Originality.ai Fact-Checker | Automated claim verification pass | From $14.95/mo |
| Winston AI | Combined hallucination flagging and source attribution | From $12/mo |
| Google Scholar | Verifying academic claims and peer-reviewed studies | Free |
| Citation Hunter (browser) | One-click source lookup for selected claims | Freemium |
| Wikipedia + References section | Launching pad to primary sources (never cite Wikipedia itself) | Free |
The full list of supporting AI content creation tools covers the broader workflow. For fact-checking specifically, pick 2 to 3 tools that fit your stack.
When AI Detection Tools Help
AI detection tools are not fact-checkers, but they correlate. Drafts that score high on AI detection also tend to contain more hallucinations because the prompt or the model is doing more of the work without human grounding. Use the detection score as a flag, not a gate.
A draft that scores 80%+ AI-generated probably needs heavier fact-checking. A draft that scores under 30% has likely been heavily edited and is more reliable to spot-check rather than line-check.
Build a Citation Library
The single highest-ROI investment in fact-check tooling is not a SaaS product. It is a shared citation library: a database of verified claims, primary sources, and the editor who verified them. The library compounds over time. After 6 months, most claims your team writes about are pre-verified, and the per-post verification cost drops to under 5 minutes.
The done-for-you SEO services we evaluated all have some version of this internal library. The presence or absence of the library is the single biggest differentiator between teams that ship fast verified content and teams that ship slow unverified content.
How This Fact-Checking System Compounds
Single-post verification matters less than the trajectory of the system. A team that verifies well today produces content that survives scrutiny today. A team that improves its verification system every month produces content that compounds in trust over quarters.
Three compounding effects to expect:
Citation library improves. Every verified claim feeds back into a shared library. After 6 months, 60% of new claims your team writes about are pre-verified. The per-post fact-check budget drops from 14 minutes to 5.
Editor pattern recognition improves. The first 100 fact-checks feel slow. By edit 500, you spot fabrication patterns inside 2 sentences. By edit 1,000, the verification pass takes half the time and catches more.
Content trust compounds. Sites that publish verified AI content for 12+ months accumulate trust signals Google reads as quality. AI Overviews cite them. Other writers cite them. Search rankings stabilize. The trust compounds in a way unverified content cannot reproduce.
The teams that win with AI content treat verification as the moat. Anyone can generate a draft. Few teams verify well enough to publish at scale. The verification system is where the durable advantage lives.
For teams that do not want to build the system internally, our content SEO module ships 30 to 80 fully-fact-checked posts per month across the exact 9-step process documented above. Every post passes through the verification system. You get the output without managing the operation.
FAQ
How long does it take to fact-check a 1,500-word AI draft?
A trained editor running the 9-step system hits 12 to 16 minutes per 1,500-word draft. The breakdown is 2 minutes for tagging, 4 minutes for statistics, 3 minutes for people and quotes, 2 minutes for URLs, 2 minutes for lateral reading, and 1 to 2 minutes for documentation. New editors run 30 to 50% longer for the first 50 drafts as pattern recognition builds.
Can AI fact-check other AI content reliably?
Partially. Automated AI fact-checkers like Originality.ai and Winston AI catch some hallucinations the human pass missed and miss some the human pass would have caught. Use them as a second pair of eyes, not as a replacement. The right workflow is human verification first, automated tool second, never the other way around. Running the tool first encourages over-reliance.
What is the biggest hallucination risk in AI content?
Fabricated expert attributions. AI models invent plausible-sounding researchers at real institutions with confident-sounding quotes. The compound fabrication defeats vertical reading because every component looks marginally plausible. Lateral reading catches them, which is why Step 5 is non-negotiable. Fabricated attributions also carry the largest reputation and legal risk.
Should I publish AI content without fact-checking if the model is highly cited as accurate?
No. Even the best models hallucinate at measurable rates on factual recall tasks. Stanford documented 17% to 33% hallucination rates across leading models in 2024. The rate has improved since but is not zero on any production model. Verification is non-negotiable. The cost is 14 minutes per draft. The cost of publishing a fabrication is months of brand repair.
How do I detect if my AI content has been fact-checked?
Check for 3 signals: every statistic links to a primary source, every named expert links to a source artifact (not their profile), and every external link resolves to a page that contains the cited claim. If any of those signals are missing, the content was not fact-checked or was fact-checked poorly. The verification level shows up clearly in the citation patterns of the published piece.
Does Google penalize AI content that contains hallucinations?
Google does not have a “hallucination penalty” specifically, but it penalizes content that fails helpful content criteria, and unverified content fails those criteria. The Google AI content policy is explicit: content quality matters, not whether AI was involved. Hallucinations are a quality failure. Pages with caught hallucinations lose rankings, lose AI Overview citations, and lose backlinks as other writers stop citing the post.
Ship Your Next AI Draft Through This System
The 9-step fact-check system takes 14 minutes per 1,500-word draft and produces content that consistently survives reader scrutiny, search engine quality reviews, and time. The system is the moat. The drafts are commodities.
Run your next AI draft through these 9 steps. Track the verification budget and the hallucination catch rate over your next 20 posts. Update the system based on what you learn. The output improves on a curve because the citation library and the editor pattern recognition both compound.
For teams that want the output without running the operation, we publish fully-verified content across 70+ industries starting at $99 per month. The same 9-step fact-check runs on every post.
Related Tools & Resources
Free SEO Tools:
Best Lists:

Written by
Siddharth GangalSiddharth is the founder of theStacc and Arka360, and a graduate of IIT Mandi. He spent years watching great businesses lose organic traffic to competitors who simply published more. So he built a system to fix that. He writes about SEO, content at scale, and the tactics that actually move rankings.
30 SEO blog articles published every month
Keyword-optimized, scheduled, and live on your site. Automatically.
30-day trial · Cancel anytime
theStacc
Stop writing SEO content manually
30 blog articles, 30 GBP posts, and social media content. Published every month. Automatically.
Try for free$1 for 3 days · Cancel anytime